


先进微器件公司推出了Instinct MI300系列数据中心人工智能加速器和支持大型语言模型(LLM)的ROCm 6软件栈。
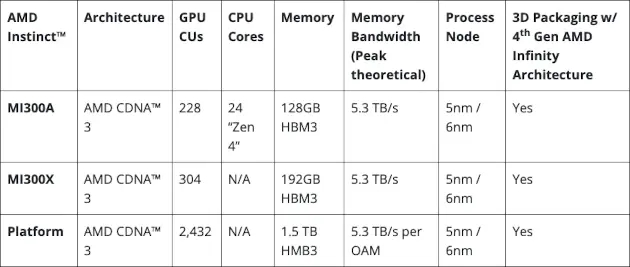
AMD Instinct MI300 模块、APU 和平台规格。来源:AMD AMD
作为支持文件的一部分,AMD 大胆宣称 MI300x 的性能超过了 Nvidia 的 H100。AMD 声称,与 Nvidia 的 H100 相比,MI300x 在 TensorFloat、浮点、块浮点和整数数据类型方面的性能优势为 32%。H100 拥有 80Gbytes 的 HBM3 内存,而 MI300X 拥有 192Gbytes 内存。
值得注意的是,MI300X 采用台积电 5 纳米和 6 纳米制造工艺技术,而 H100 则采用台积电 4N 工艺(4 纳米)。
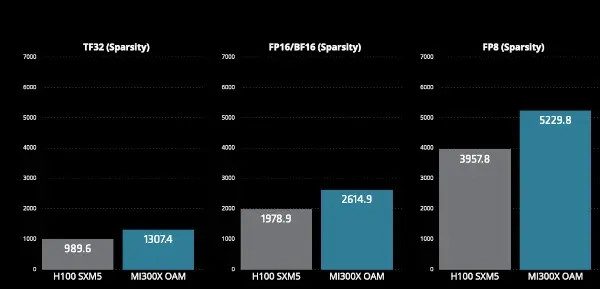
按数据类型分列的 MI300X AI 性能(峰值 TFLOPs)。来源:AMD 来源:AMD
MI300 采用 AMD 的 CDNA3 GPU 架构,使用晶圆代工厂台积电的 5 纳米和 6 纳米 FinFET 工艺技术制造。该组件拥有 19,456 个流处理器和 304 个计算单元,最高时钟频率为 2.1GHz。FP16 峰值性能为 1.3PFLOPS,INT8 峰值性能为 2.6POPS。
该组件通过 OCP Accelerator Module(OAM)提供,并采用被动冷却方式。该模块包括 192 Gbytes 的 HBM3 内存,峰值理论内存带宽为每秒 5.3 Tbytes。
与 MI250 上运行的 ROCm 5 相比,ROCm 6 支持新的数据类型、高级图形和内核优化、优化库和最先进的注意力算法,与 MI300X 一起在 Llama 2 上生成文本的整体延迟性能提高了约 8 倍。
APU 和平台
AMD Instinct MI300A是一款加速处理单元(APU),它的Instinct加速器数量较少,但包含了具有共享内存的Epyc处理器,从而提高了效率、灵活性和可编程性。它们旨在加速人工智能与高性能计算的融合。
MI300A 包括 228 个计算单元和 24 个 Zen 4 x86 CPU 内核,以及 128Gbytes HBM3 内存。
AMD Instinct 平台是一个生成式人工智能平台,配备 8 个 MI300X 加速器,提供 1.5Tbytes 的 HBM3 内存容量。与 Nvidia H100 HGX 相比,AMD Instinct 平台在 BLOOM 176B 等 LLM 上运行推理时,吞吐量最多可提高 1.6 倍。AMD 声称,它是市场上唯一能够在单个 MI300X 加速器上运行 700 亿参数模型(如 Llama2)推理的选择。
多少钱?
此前,Nvidia 的 H100 已被公认为数据中心中用于训练和推理的性能最高的人工智能 GPU 处理器。据 Nvidia 称,H100 在行业标准 MLPerf 基准测试中创造了性能记录,是其 A100 性能的 4.5 倍。据报道,H100 通常用于自然语言处理、计算机视觉和生成式人工智能,价格在 2.5 万至 4 万美元之间。
美国政府认为,H100 和 A100 性能太强,在没有出口许可证的情况下不能出口到中国和其他一些国家。
"AMD 董事长兼首席执行官苏姿丰(Lisa Su)在一份声明中表示:"我们看到市场对我们全新的 Instinct MI300 GPU 的需求非常强劲,它是世界上用于生成式人工智能的最高性能加速器。"我们还与最大的云计算公司、业界顶级的服务器提供商以及最具创新精神的人工智能初创企业密切合作,为我们的数据中心人工智能解决方案创造了巨大的发展势头,我们将迅速向市场推出Instinct MI300解决方案,这将大大加快整个人工智能生态系统的创新步伐。"
在发布会上,AMD提到微软、戴尔科技、惠普企业、联想、Meta、甲骨文、超微等公司采用AMD Instinct MI300x和MI300a数据中心人工智能加速器作为训练和推理解决方案。



